Query Feed for Jira
The Query Feed for Jira add-on exposes Jira issues as direct JSON, CSV or TSV resources. The data can be directly imported to a database, spreadsheet, or easily consumed with any application, server- or client-side.
The native Jira API is very powerful, but at the same time it's hard to consume and comes with rigid security model. Query Feed for Jira solves these problems: It exposes just the data you need, is directly accessible from any application, and has security that no longer gets in the way.
How does it work?
You can create a number of configurations. Each of them defines a Jira query that determines what issues will be exported, as well as the fields that will be included in the data feed.
Query Feed for Jira will export the selected fields for matching issues and provide a URL to the data. It supports cross-origin resource sharing (CORS), making it possible to consume the data directly from a client-side web application. Of course feeds can also be consumed by server-side code.
The data link does not does not require authentication, providing maximum accessibility and letting you keep your Jira credentials safe. The URL contains an access token which can be re-generated at any time from the administration screen, invalidating the previous one.
The data underlying the feed URL will be updated periodically and stay up-to-date with Jira. It does not require any other actions or configuration. The URL only changes when the token is invalidated.
Alternatively, each query feed can be configured to push updates to an external HTTP(S) resource every time the data is updated.
Configuration
Query feeds
The Query feeds page shows all query feeds along with their status.
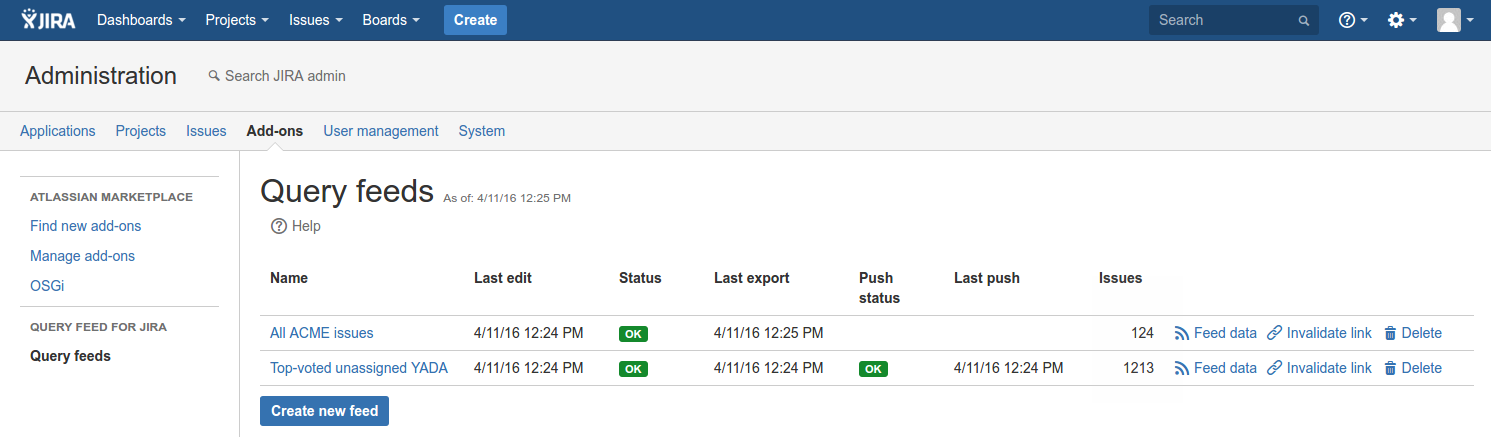
It includes the following columns:
Name - the name of the feed
Last edit - When it was last edited.
Status - status of the last export.
Last export - date and time of the last export.
Push status - status of the last "push" attempt (if configured).
Last push - time of the last "push" attempt (if configured).
Issues - how many Jira issues were exported. Please note that the Query Feed for Jira currently limits each feed to 5,000 issues.
The following actions are available:
Create new feed - creates a new feed.
Edit feed - click feed name to review and update its configuration.
Feed data - click to view feed data in a new tab. The data URL is the location that should be used to read feed data from your application.
Invalidate link - re-generate access token for this feed (included in the URL). The token is required to access the data, and invalidation makes old URLs inaccessible.
Delete - permanently remove the feed.
If the feed is working as expected, the status column displays a green "OK" label. Otherwise it shows a red "ERROR" badge.

An error means that the feed could not exported. Older versions of the export may still be available for download (if it was successful in the past). Errors may occur for a number of reasons, including problems with reaching Jira, feed misconfiguration or internal problems within Query Feed for Jira.
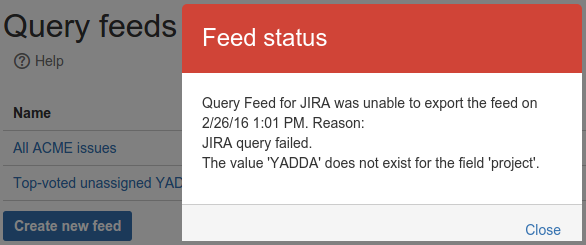
Click the "ERROR" badge to find out more about the problem. In the example pictured below, the error occurred because the JQL query in feed configuration was invalid.
Editing feeds
This section documents the feed detail page which is used for creating and editing feeds. The configuration form is shown below.
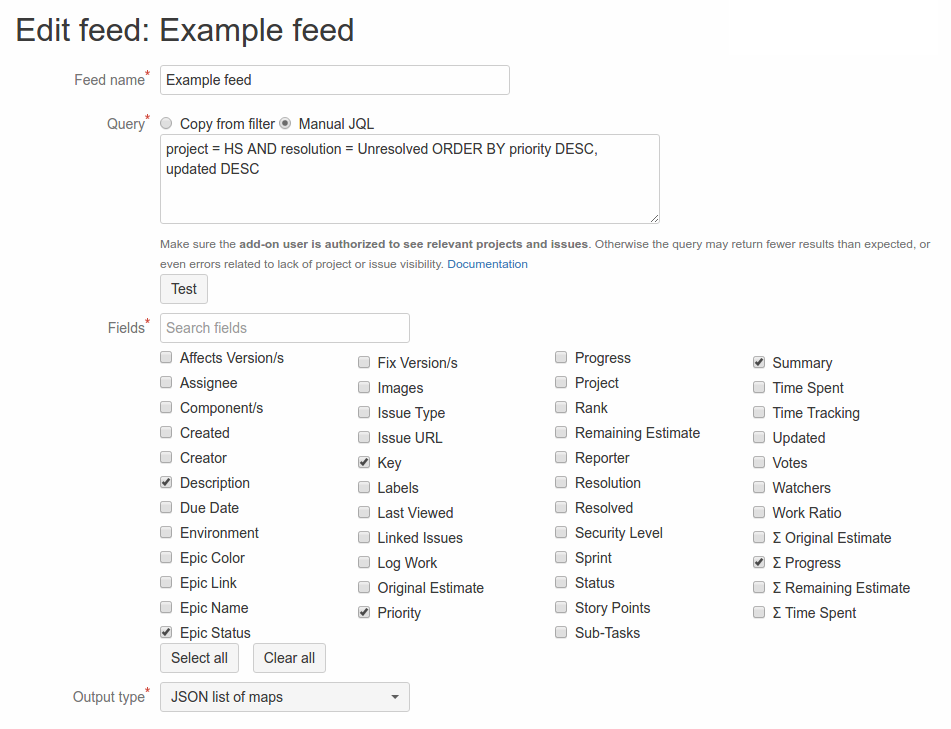
Each feed is given a unique Feedname. This name will be used as a label on the app pages.
The Query determines what Jira issues will be included in the feed. You can select an existing favorite filter, or enter the Jira Query Language (JQL) query directly. Tip: to obtain a ready-to-use query without creating a favorite filter, you can use the Jira issue search and click the "Advanced" link to get the corresponding JQL clause.
With manual JQL input, you can test the query using the Test button. It will display the total number of matching issues, or an error message if the query is invalid.
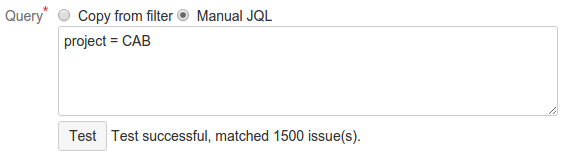
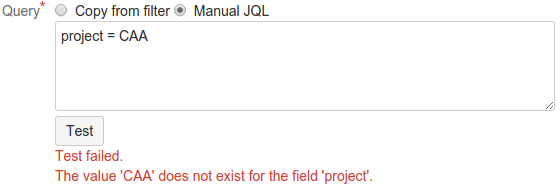
The example error shown above can occur because the project does not exist or because the synthetic user created by Jira to represent Query Feed does not have access to it. See Security in Query Feed for details and work with your Jira administrator to configure access.
Use the Fields section to configure what fields are included in the export. Only the selected fields will be included. Please note that the more fields are included, the larger the data feed. This may have an impact on bandwidth usage and performance of the application consuming the feed.
The Output type configures in what format the data will be exported. The following options are available:
JSON list of maps - data represented as an array of objects (maps)
JSON map of maps - data represented as a map of maps, indexed by issue key
CSV - plain text, comma-separated
TSV - plain text, tab-separated
See Query feed data to learn more about output formats.
Testing configuration
At the bottom of the form, there is a Test button that can be used to review the export results before saving changes. The button is available as soon as the form is valid (e.g. all the required fields are set).
For performance reasons, the export will be based on a sample of all the issues matching the query, but the items will have the same shape as what will be exported after the configuration is saved.
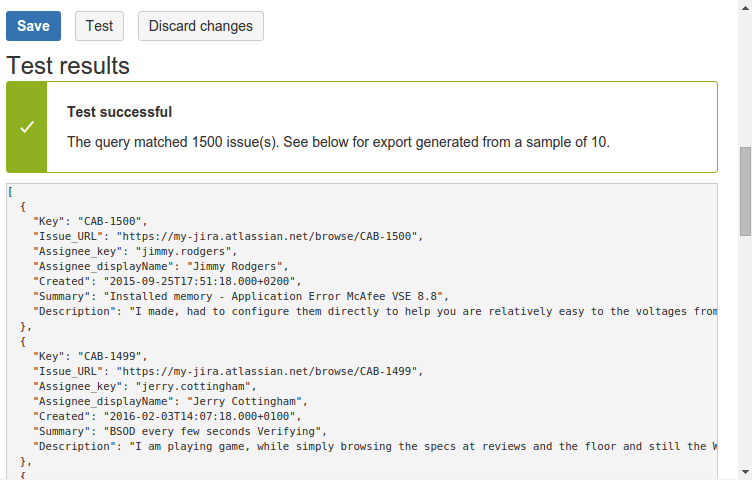
Query Feed Data
The exported data is available from the Query Feeds page. The data URL is freely accessible from the outside (until the link is invalidated). It can even be called directly by client applications thanks to cross-origin resource sharing (CORS) support. Query feed can also be configured to push the data to an external HTTP(S) endpoint whenever it is updated.
JSON
The picture below shows sample data feed as JSON list of maps (on the left) and JSON map of maps (on the right).

The data includes the following fields:
feedId - internal ID of the feed
lastSuccess - time of last successful export
lastError - time of last failed export
data - all exported issues, as an array of objects or a map of objects
lastErrorData - information about the last error, if any
issueCount - total number of issues in feed
nextRefresh - the latest time when the data will be refreshed; this value may change over time. For example, the feed is refreshed at most a few minutes after an issue is created or edited in Jira
The issue objects are flat key-value pairs, with keys corresponding to field names and values extracted from Jira issue fields. The names are normalized in such a way that they are valid identifiers in most programming languages (for easier consumption). If a field has more than one useful property (like project or user), all of them will be exported. See the image above for an example.
CSV and TSV
The following screenshot demonstrates what the data in CSV or TSV format looks like after import to a spreadsheet program.

The columns correspond to Jira issue fields, whose names are subject to the same normalization process as in the case of JSON. Each row corresponds to one issue.
When CSV or TSV format is chosen, the feed includes just the exported issue data in selected format. It does not include any other information as is the case with JSON, such as feed ID, export time, issue count etc.
Comparison to Jira REST API
Even though Jira already provides a rich REST API, there are several reasons why Query Feed may be a better choice.
Streamlined data model
Query Feed for Jira has been built to make access to Jira issue data as easy as possible.
It includes only the information you configured (based on a query and field selection).
All data is available at a single URL.
The data is in a format that is very easy to consume. It does not require you to understand complex field metadata and use it to interpret Jira issues. All the information is directly available in a flat JSON map, matching field names with values.
See Configuration in Query Feed for more information.
Available anywhere with a simple security model
With Query Feed for Jira, the data can be easily consumed from any source - but it is still secure!
It does not require any authentication (login/password or OAuth) or setup procedures, except for an access token, which is part of the feed URL.
Query Feed data is always served over HTTPS, protecting the access token and data from interception.
The data can be immediately and easily downloaded from any source. It may be consumed by a batch process or even a lightweight script. It may even be used directly from a serverless web application thanks to cross-origin resource sharing.
Only selected fields from issues matching the feed query are exposed.
Query Feed cannot be used to make any modifications in Jira. At the same time there is an easy way to prevent access to feed data by invalidating the access token.
Data push
All data feeds created by Query Feed are always available for download via HTTPS GET request. This is sometimes referred to as the pull model.
In addition to that, the add-on can be configured to push feed data every time it changes to a remote HTTP or HTTPS endpoint. The target must be able to receive such requests from the Internet and interpret them. Query Feed provides data in a number of generic and widely-supported formats, but it may still be necessary to transform it for use with some applications.
When enabled, every push includes complete feed data set - the same that is available for download via feed URL. The feeds are typically refreshed within 5 minutes from a change in underlying Jira issues. If Jira is updated more frequently, Query Feed will "accumulate" several changes to a single update.
Use the "Data push" configuration section to configure the HTTP method (POST or PUT) and target URL.
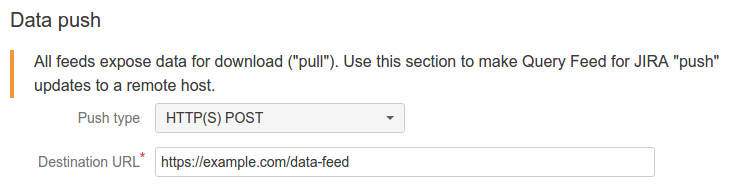
When data push is configured, the feed status page indicates the status and time of last push.
If the last push attempt has failed, the status column displays a red "ERROR" badge. Click it to learn more about the problem, including server response (if one is available).
Update Schedule
Query Feed supports two types of update schedule:
Automatic refreshes the feed within a few minutes after Jira issue data is updated. This way the data stays up to date. However, the extraction process itself can cause significant load for large data feeds. This setting is recommended for smaller feeds, typically up to a few thousand issues.
Cron schedule updates the feed at specific time and day. It gives the administrator full control over when the updates occur. They can be scheduled for a time with less user activity, or configured with lower frequency to minimize performance impact. See below for more information on using cron expressions.
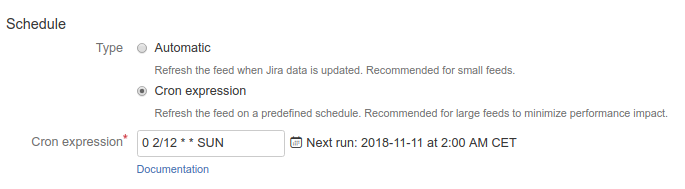
Cron schedule
This page is based on Atlassian scheduling documentation. However, please note that there are some differences between what is supported for Jira Cloud and DC.
Cron schedule is defined with a short expression of 5 or 6 space-separated fields. Each position corresponds to a time or date component.
For example, the following expression would schedule the job for 2:15 AM every Monday, Wednesday and Friday:
15 2 * * MON,WED,FRI
The fields are (in order from left to right):
Second | Minute | Hour | Day of month | Month | Day of week | |
|---|---|---|---|---|---|---|
Allowed values | 0-59 | 0-59 | 0-23 | 1-31 | 1-12 | SUN-SAT |
Allowed special characters | , - * / | , - * / | , - * / | , - * / | , - * / | , - * / |
The date and time of execution depend on server's time zone.
For Jira DC the updates will be executed in your server time zone.
For Jira Cloud the updates are executed in US Central Time (Chicago).
Special Characters
Special character | Usage |
|---|---|
, | Specifies a list of values. For example, in the Day of week field, "MON, WED, FRI" means "every Monday, Wednesday, and Friday". |
- | Specifies a range of values. For example, in the Day of week field, "MON-FRI" means "every Monday, Tuesday, Wednesday, Thursday and Friday". |
* | Specifies all possible values. For example, in the Hour field, "*" means "every hour of the day". |
/ | Specifies increments to the given value. For example, in the Minute field, "0/15" means "every 15 minutes during the hour, starting at minute zero". |
Examples
Expression | Interpretation |
|---|---|
| Every day at 8:15 am. |
| Every minute starting at 2:00 pm and ending at 2:59 pm, every day. |
| Every 5 minutes starting at 2:00 pm and ending at 2:55 pm, every day. |
| Every 5 minutes starting at 2:00 pm and ending at 2:55 pm, AND every 5 minutes starting at 6:00 pm and ending at 6:55 pm, every day. |
| Every minute starting at 2:00 pm and ending at 2:05 pm, every day. |
| Every 10 minutes, forever. |
| 2:10 pm and 2:44 pm every Wednesday in March. |
| 8:15 am every Monday, Tuesday, Wednesday, Thursday, and Friday. |
| 8:15 am on the 15th day of every month. |
Environment-specific features
Jira Cloud
Query Feed for Jira Cloud supports only the types of expressions documented in the previous section. If you're already familiar with cron, note that the following are not supported at this point:
Repetition starts with a specific value, such as "0 2/12 * * *" for 2 AM and 2 PM. In this case, you can use "0 */12 * * *" (12 AM/PM) or "0 2,14 * * *".
The "L" (last value), "W" (weekday) and "#" (nth occurrence) special characters.
Jira Server
In addition to the basic cron expressions explained above, Jira Server supports more complex features. See below for a complete list of allowed characters and their meaning.
Second (optional) | Minute | Hour | Day of month | Month | Day of week | |
|---|---|---|---|---|---|---|
Allowed values | 0-59 | 0-59 | 0-23 | 1-31 | 1-12 | SUN-SAT 1-7 (1 for Sunday, 7 for Saturday) |
Allowed special characters | , - * / | , - * / | , - * / | , - * / ? L W C | , - * / | , - * / ? L C # |
The additional special characters are:
Special character | Usage |
|---|---|
? | Specifies no particular value. This is useful when you need to specify a value for one of the two fields, Day of month or Day of week, but not the other. This special character is supported for Jira DC. However, it is rather confusing and Query Feed allows using "*" for all fields instead. |
L | Specifies the last possible value; this has different meanings depending on context. In the Day of week field, 'L' on its own means "the last day of every week" (i.e. "every Saturday"), or if used after another value, means "the last xxx day of the month" (e.g. "7L" means "the last Saturday of the month"). In the Day of month field, "L" on its own means "the last day of the month", or "LW" means "the last weekday of the month". |
W | Specifies the weekday (Monday-Friday) nearest the given day of the month. For example, "1W" means "the nearest weekday to the 1st of the month" (note that if the 1st is a Saturday, then it represents the nearest weekday within the same month, i.e. Monday the 3rd). "W" can only be used when the day of the month is a single day, not a range or list of days. |
# | Specifies the nth occurrence of a given day of the week. For example, "TUE#2" means "the second Tuesday of the month". |
See below for more complex expressions available on Jira DC.
Expression | Interpretation |
|---|---|
| Every 10 minutes starting at 2:05 pm and ending at 2:55 pm, every day. |
| 8:15 am on the last day of every month. |
| 8:15 am on the last weekday of every month. |
| 8:15 am on the last Friday of every month. |
| 8:15 am on the second Friday of every month. |
Security
Jira access security
Query Feed for Jira does not update any data in Jira, it is a read-only exporter. Only read access is needed.
Jira Cloud
During the installation, Jira Cloud will create an artificial "user" representing the add-on in the system. The user is called "Query Feed" and is visible in User Management like a regular user account (but it does not count toward the user limit). The add-on will use this account to read data from Jira and generate query feeds.
To control what the add-on can see, adjust the permissions of this artificial user. If your Jira is configured in a way that does grant new users access to some information, it will be necessary to configure the permissions before using Query Feed for Jira. Otherwise, the add-on will be unable to run queries, showing fewer issues than expected or even errors related to a lack of project or issue visibility.
Jira DC
When used in Jira DC, Query Feed performs all operations as the user who is currently logged in. When a feed is exported, it will continue to use the access rights of the user who created it. If the rights of this user to see some data are limited, it will affect the exported feeds as well.
Feed data security
The data URL provided by Query Feed for Jira is freely accessible. It contains an access token, which is the only means of access control. Thanks to transport layer security (with HTTPS), the link, token, and data are safe from eavesdropping.
Each feed only exposes issues matched by a specific query, and only the configured fields. No other data is exported and potentially exposed.
Each feed has its own unique URL and access token. There is no risk of using the information about one feed to access data for another. The token can be invalidated and re-generated at any time, making the data inaccessible from the old URL.
The add-on supports CORS (cross-origin resource sharing), so the data URL can even be accessed directly by a serverless client-side web application. However, remember that in this case any user of the application may obtain the link and get access to the data directly. This approach is only recommended for cases when the data is effectively public anyway (for example exposed on a public website) or used by a narrow, trusted user base.
When more security is needed, you should keep the data URL safe on the server side of your application, and only expose data to authenticated users of your application.
The same advice applies to systems that use this data for some other processing (for example, analytics). Be aware that the URL contains all credentials necessary for data access, and keep it safe when needed.